Computation Caching
Before reading this guide, check out the mental model guide. It will help you understand how computation caching fits into the rest of Nx.
Overview
It's costly to rebuild and retest the same code over and over again. Nx uses a computation cache to never rebuild the same code twice. This is how it does it:
Before running any task, Nx computes its computation hash. As long as the computation hash is the same, the output of running the task is the same.
By default, the computation hash for say nx test app1 includes:
- All the source files of
app1and its dependencies - Relevant global configuration
- Versions of external dependencies
- Runtime values provisioned by the user
- CLI Command flags
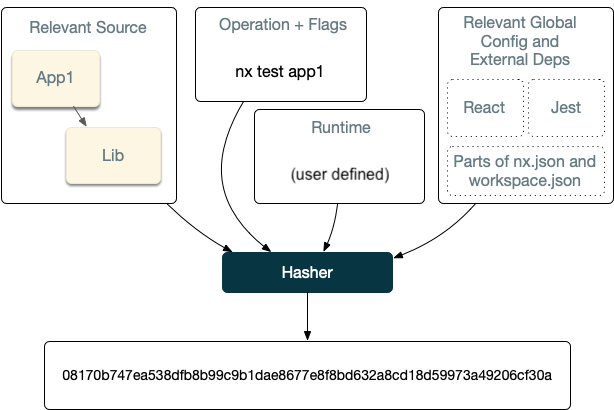
This behavior is customizable. For instance, lint checks may only depend on the source code of the project and global configs. Builds can depend on the dts files of the compiled libs instead of their source.
After Nx computes the hash for a task, it then checks if it ran this exact computation before. First, it checks locally, and then if it is missing, and if a remote cache is configured, it checks remotely.
If Nx finds the computation, Nx retrieves it and replay it. Nx places the right files in the right folders and prints the terminal output. So from the user’s point of view, the command ran the same, just a lot faster.
If Nx doesn’t find this computation, Nx runs the task, and after it completes, it takes the outputs and the terminal output and stores it locally (and if configured remotely). All of this happens transparently, so you don’t have to worry about it.
Although conceptually this is fairly straightforward, Nx optimizes this to make this experience good for you. For instance, Nx:
- Captures stdout and stderr to make sure the replayed output looks the same, including on Windows.
- Minimizes the IO by remembering what files are replayed where.
- Only shows relevant output when processing a large task graph.
- Provides affordances for troubleshooting cache misses. And many other optimizations.
As your workspace grows, the task graph looks more like this:
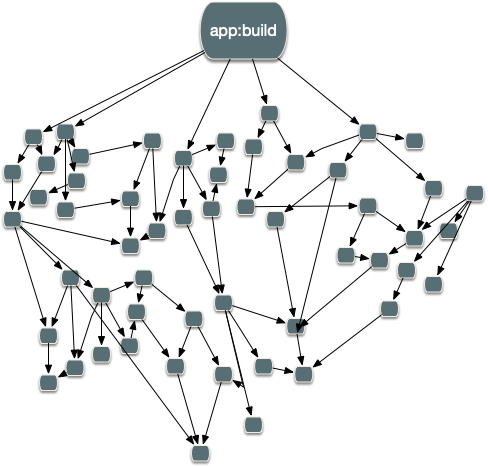
All of these optimizations are crucial for making Nx usable for any non-trivial workspace. Only the minimum amount of work happens. The rest is either left as is or restored from the cache.
Source Code Hash Inputs
The result of building/testing an application or a library depends on the source code of that project and all the source codes of all the libraries it depends on (directly or indirectly). It also depends on the configuration files like package.json, nx.json, tsconfig.base.json, and package-lock.json. The list of these files isn't arbitrary. Nx can deduce most of them by analyzing our codebase. Few have to be listed manually in the implicitDependencies property of nx.json.
1{
2 "npmScope": "happyorg",
3 "implicitDependencies": {
4 "global-config-file.json": "*"
5 },
6 "tasksRunnerOptions": {
7 "default": {
8 "options": {
9 "cacheableOperations": ["build", "test", "lint", "e2e"]
10 }
11 }
12 }
13}Runtime Hash Inputs
All commands listed in runtimeCacheInputs are invoked by Nx, and the results are included into the computation hash of each task.
1{
2 "npmScope": "happyorg",
3 "tasksRunnerOptions": {
4 "default": {
5 "options": {
6 "cacheableOperations": ["build", "test", "lint", "e2e"],
7 "runtimeCacheInputs": ["node -v", "echo $IMPORTANT_ENV_VAR"]
8 }
9 }
10 }
11}Sometimes the amount of runtimeCacheInputs can be too overwhelming and difficult to read or parse. In this case, we
recommend creating a SHA from those inputs. It can be done like the following:
1{
2 "npmScope": "happyorg",
3 "tasksRunnerOptions": {
4 "default": {
5 "options": {
6 "cacheableOperations": ["build", "test", "lint", "e2e"],
7 "runtimeCacheInputs": [
8 "node -v",
9 "echo $IMPORTANT_ENV_VAR",
10 "echo $LONG_IMPORTANT_ENV_VAR | sha256sum",
11 "cat path/to/my/big-list-of-checksums.txt | sha256sum"
12 ]
13 }
14 }
15 }
16}Args Hash Inputs
Finally, in addition to Source Code Hash Inputs and Runtime Hash Inputs, Nx needs to consider the arguments: For example, nx build shop and nx build shop --prod produce different results.
Note, only the flags passed to the executor itself affect results of the computation. For instance, the following commands are identical from the caching perspective.
nx build myapp --prod
nx build myapp --configuration=production
nx run-many --target=build --projects=myapp --configuration=production
nx run-many --target=build --projects=myapp --configuration=production --parallel
nx affected:build # given that myapp is affectedIn other words, Nx does not cache what the developer types into the terminal. The args cache inputs consist of: Project Name, Target, Configuration + Args Passed to Executors.
If you build/test/lint… multiple projects, each individual build has its own hash value and is either be retrieved from cache or run. This means that from the caching point of view, the following command:
nx run-many --target=build --projects=myapp1,myapp2is identical to the following two commands:
nx build myapp1
nx build myapp2What is Cached
Nx works on the process level. Regardless of the tools used to build/test/lint/etc.. your project, the results is cached.
Nx sets up hooks to collect stdout/stderr before running the command. All the output is cached and then replayed during a cache hit.
Nx also caches the files generated by a command. The list of folders is listed in the outputs property.
1{
2 "projects": {
3 "myapp": {
4 "root": "apps/myapp/",
5 "sourceRoot": "apps/myapp/src",
6 "projectType": "application",
7 "architect": {
8 "build": {
9 "builder": "@nrwl/js:tsc",
10 "outputs": ["dist/apps/myapp"],
11 "options": {
12 "main": "apps/myapp/src/index.ts"
13 }
14 }
15 }
16 }
17 }
18}If the outputs property is missing, Nx defaults to caching the appropriate folder in the dist (dist/apps/myapp for myapp and dist/libs/somelib for somelib).
Skipping Cache
Sometimes you want to skip the cache, such as if you are measuring the performance of a command. Use the --skip-nx-cache flag to skip checking the computation cache.
nx build myapp --skip-nx-cache
nx affected --target=build --skip-nx-cacheCustomizing the Cache Location
The cache is stored in node_modules/.cache/nx by default. To change the cache location, set a NX_CACHE_DIRECTORY environment variable or update the cacheDirectory option for the task runner:
1{
2 "npmScope": "happyorg",
3 "tasksRunnerOptions": {
4 "default": {
5 "options": {
6 "cacheableOperations": ["build", "test", "lint", "e2e"],
7 "cacheDirectory": "/tmp/nx"
8 }
9 }
10 }
11}Local Computation Caching
By default, Nx uses a local computation cache. Nx stores the cached values only for a week, after which they are deleted. To clear the cache run nx reset, and Nx creates a new one the next time it tries to access it.
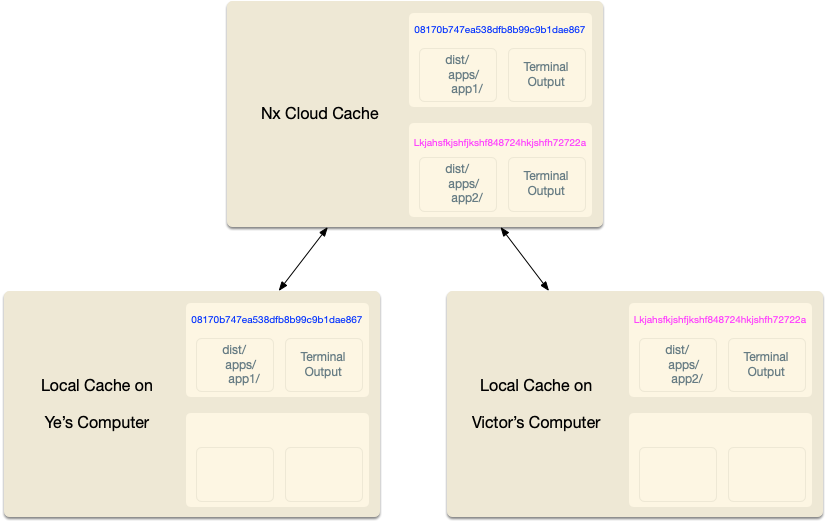
Distributed Computation Caching
The computation cache provided by Nx can be distributed across multiple machines. Nx Cloud is a product that allows you to share the results of running build/test with everyone else working in the same workspace. Learn more at https://nx.app.
You can connect your workspace to Nx Cloud by running:
nx connect-to-nx-cloudYou can also distribute the cache manually using your own storage mechanisms. Be warned, it is not as simple as it might sound initially.
- If possible, pull a copy of the cache which doesn't mutate the cache currently in use by other consumers. Push an updated copy afterwards.
- By default, Nx also caches some computations necessary for calculating the project graph in the cache directory as well.
- If you are using a shared volume where mutations to the cache are reflected immediately in other consumers, you should set
NX_PROJECT_GRAPH_CACHE_DIRECTORYto a separate directory to separate it from the computation cache.
- If you are using a shared volume where mutations to the cache are reflected immediately in other consumers, you should set
Caching Priority
Whenever you run a cacheable command with Nx, Nx attempts to fulfill that command using the first successful strategy in the following list:
- Check the local cache. If the command is cached there, replay the cached output.
- Check the Nx Cloud distributed cache. If the command is cached there, store the cache locally and replay the cached output.
- Run the command locally. Store the output in local cache. If you have a read-write access token, store the output in the Nx Cloud distributed cache.
This algorithm optimizes for speed locally and minimizes unnecessary use of the distributed cache.
When is a Distributed Cache Helpful?
Generally speaking, the bigger the organization, the more helpful a distributed cache becomes. However, distributed cache is still useful even in the following scenarios with two developers and a CI/CD machine.
Scenario 1: Help Me Fix This Bug
Perry works on a feature, but he can't figure out why it isn't working the way he expects. Neelam checks out that branch to help. Neelam doesn't need to re-run all the tests that Perry already ran.
Scenario 2: Why Is This Breaking in CI?
Tony pushes a branch up to CI, but CI doesn't pass. He asks Sofija to help. Sofija checks out that branch to troubleshoot. Sofija can reuse the output from CI instead of waiting for builds to run on her machine.
Scenario 3: CI Should Know It Already Did That
Maya and Trey push up changes to two different apps that both depend on an unchanged shared buildable library. CI reuses the build output of the shared buildable library when building the apps in the two different PRs.
Example
- This is an example repo benchmarking Nx's computation caching. It also explains why Nx's computation caching tends to be a lot faster than the caching of other build systems.